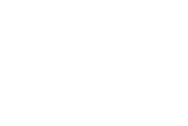







Il nuovo modello architetturale delle applicazioni software nel Data Center
Il nuovo modello di gestione del traffico: da Nord-Sud a Est-Ovest
Il nuovo modello di gestione del traffico: da Nord-Sud a Est-Ovest
Un nuovo modello di gestione del traffico si rende necessario vista l’evoluzione delle modalità di erogazione di servizi e applicazioni. Nel modello tradizionale, la maggior parte delle transazioni riguarda le comunicazioni tra client e server, quindi con una direzionalità di traffico entrante/uscente rispetto al data center che ospita la server farm, il cosiddetto traffico verticale, anche definito Nord – Sud. Con il modello applicativo sempre più rivolto alle architetture a microservizi, si innescano movimenti di traffico aggiuntivi tra le componenti stesse applicative dislocate su più elementi di elaborazione: VM, Container, Could, Serverless Computing. È traffico orizzontale, definito Est-Ovest. Cambiando il modello del data center che eroga i servizi, cambiano anche gli aspetti del networking che sostengono il movimento del traffico, tra cui i dispositivi di delivery del traffico ai server, appunto basati sulle tecnologie ADC. La questione della gestione del traffico secondo i nuovi modelli si pone a fronte della costruzione di applicazioni disaggregate, frutto dello sviluppo con metodologia agile, rispetto all’impiego delle applicazioni monolitiche del passato.
La dislocazione dei microservizi e il ruolo dell’IT
La dislocazione dei microservizi e il ruolo dell’IT
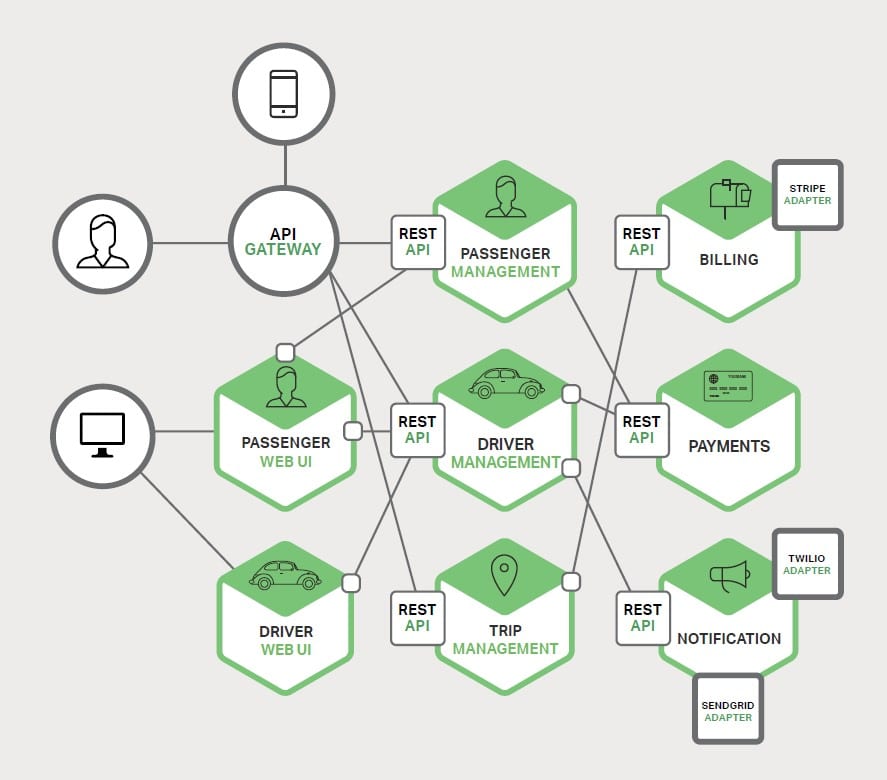
Microservizi in Container è la soluzione che risponde a tali esigenze di sviluppo delle applicazioni. La suddivisione dell’applicazione in più parti che operano insieme per fornire il servizio completo. La suddivisione che permette agli sviluppatori di intervenire sulle parti indipendentemente da ciascuna di esse. Lo schema rappresentato in figura evidenzia le varie aree funzionali di un’applicazione, ciascuna realizzata attraverso l’esecuzione del proprio microservizio, ognuno connesso attraverso la propria interfaccia API con accesso da parte delle applicazioni degli utenti intermediato da un API Gateway, che fa fronte alle esigenze di load balancing, caching, access control, metering e monitoring, ossia svolge il ruolo del ADC. Il risultato è l’applicazione che diventa più leggera e maggiormente gestibile con maggior facilità di rinnovamento rispetto alla staticità e complessità del passato. Ma il risultato di maggior dinamicità per il team di sviluppo si riflette su una maggiore pressione per il team operativo che gestisce l’infrastruttura del DC: è necessario che vengano adottate le tecnologie adeguate a supportare i nuovi modelli di traffico. Nei nuovi modelli applicativi un quantitativo di container individuali che implementano i vari servizi, produce l’esigenza di interconnetterli per consentire la comunicazione tra le loro interfacce API, come evidenzia il suddetto schema. Il modello favorisce la scalabilità dinamica: in base alle esigenze di disponibilità e carico da smaltire possono essere clonate più copie dell’applicazione dietro al controllo di un load balancer che governa l’accesso ai relativi Container, come indica lo schema seguente.
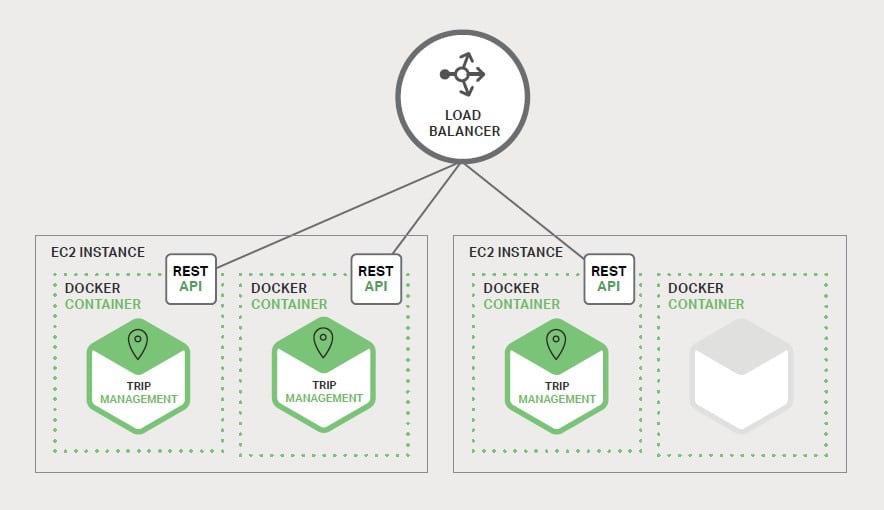
Tuttavia, la dislocazione dell’applicazione costituita da microservizi in una infrastruttura IT porta ad una certa complessità, poiché a differenza di un’applicazione monolitica, realizzata con un certo numero di server identici pilotati dai load balancer tradizionali, si è invece in presenza di un gran numero di servizi, ciascuno potenzialmente con più copie attive simultaneamente, ciò comporta il controllo di molte più componenti che devono essere configurate, dislocate, monitorate e gestite in modo scalabile, in aggiunta all’impiego di opportuni meccanismi di “service-discovery” che permettano a ciascun servizio di localizzare gli altri servizi, attraverso coordinate di comunicazione con host e porte di qualsiasi altro servizio con cui è necessario interagire. L’approccio manuale all’implementazione basato sull’inserimento di relativi service ticket per realizzare l’ambiente operativo non è proponibile a questi livelli di complessità. Affinché si conduca con successo un progetto di dislocazione dei microservizi è necessario che vi sia un marcato controllo dei meccanismi di implementazione da parte degli sviluppatori stessi, che implica un elevato livello di automazione. Infatti, gli approcci più comuni comportano l’uso di piattaforme PaaS come OpenShift e Cloud Foundry, in grado di fornire agli sviluppatori gli strumenti utili alla dislocazione e gestione dei microservizi da loro sviluppati, isolandoli da problemi che riguardano l’acquisizione e la configurazione delle relative risorse dell’infrastruttura IT. D’altro canto, i tecnici dei sistemi e della rete, possono attivare le apposite tecnologie PaaS in conformità con le politiche e pratiche tecnologiche aziendali. In questi contesti non è raro trovare implementazioni che sfruttano le tecnologie di realizzazione e gestione dei cluster di container come Kubernetes in combinazione con Docker per realizzare le piattaforme di attivazione dei microservizi, dove diventa cruciale l’impiego di tecnologie di application delivery con un approccio basato sul software, direttamente integrato per la gestione dei microservizi.
Load Balancing e API Gateway: dal modello tradizionale all’architettura a microservizi
Load Balancing e API Gateway: dal modello tradizionale all’architettura a microservizi
Con l’approccio tradizionale, un’applicazione web risponde a specifiche richieste che vengono indirizzate attraverso i load balancer ai server, ad esempio, una richiesta come la seguente:
GET application.company.com/productdetails/productId
genera da parte del load balancer l’instradamento verso uno dei server nel gruppo della server farm dell’applicazione, quindi l’elaborazione della richiesta genera una serie di acquisizioni di dati e tabelle disponibili sul database, per restituire così la risposta al client.
In contrapposizione a questo modello, con l’architettura a microservizi i dati che vengono infine visualizzati sulla pagina del client sono controllati da multipli servizi individuali, come rappresentato dallo schema seguente.
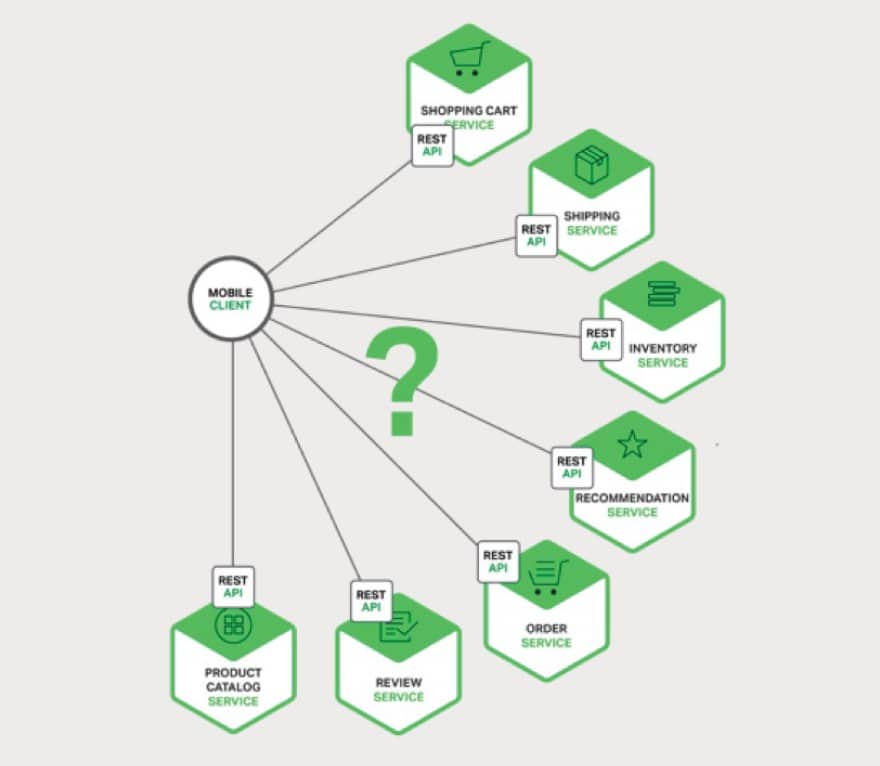
C’è quindi una maggiore articolazione nella gestione della modalità d’accesso da parte del client. Teoricamente quest’ultimo potrebbe interfacciare ogni servizio direttamente chiamando le apposite API e componendo la pagina da visualizzare, ma è un approccio non pratico e non è scalabile e se tollerabile in LAN, soprattutto non lo è in un ambito di utilizzo via Internet oppure in rete mobile, oltre a rendere il codice applicativo per la parte client più complesso. Senza tenere conto oltretutto delle difficoltà nella ristrutturazione o refactoring del codice del software. Per queste ragioni l’interfacciamento non avviene in modo diretto, ed entra in gioco la funzione del API Gateway, ossia un server che rappresenta il punto d’ingresso verso il sistema applicativo. Questo server fornisce l’interfaccia API per i client rendendo trasparente l’architettura di API dei microservizi ed inoltre si fa carico di altre funzioni a supporto delle comunicazioni, ad esempio:
- Autenticazione
- Monitoraggio
- Load Balancing
- Caching
- Request Shaping
- Static Response Delivery.
Inoltre, riceve le richieste dai client e le instrada in modo appropriato verso i microservizi, anche aggregando le risposte, eventualmente traducendo i protocolli interni se non ottimizzati per la gestione delle richieste via Web.